RAG 시스템을 위한 청킹 방법론
저자: 김성중 · 작성일: 2025-09-12 00:00:00 · 분야: LLM
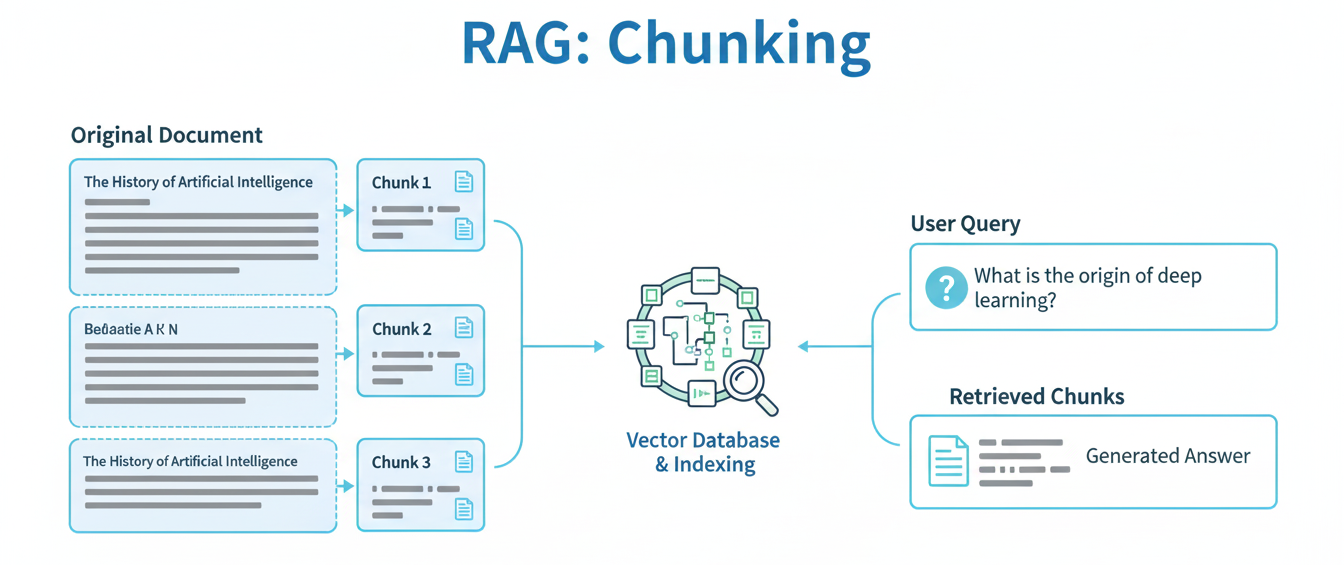
청킹은 RAG 파이프라인에서 단순한 역할에도 불구하고 시스템의 전체 성능에 막대한 영향을 미친다.
첫째, 적절한 청크는 정보 검색의 효율성과 정확성을 향상시킨다. 둘째, LLM이 가진 제한적인 컨텍스트 윈도우 크기 문제를 해결하고, 더불어 불필요한 토큰 처리를 줄여 계산 비용을 절감하는 데 기여한다.
RAG 시스템의 성능 저하가 종종 검색 모델 자체가 아닌 청킹 방식에 기인한다고 지적하며, 청킹이 단순히 전처리 단계가 아니라 RAG 파이프라인의 전체 성능을 결정하는 가장 중요한 부분이다.

Chunking 방법론
- 고정 길이 청킹 (Fixed-Length Chunking): 가장 단순하고 널리 사용되는 방법이다. 문서의 자연스러운 논리적 구조를 고려하지 않고, 지정된 문자 또는 토큰 수에 따라 텍스트를 기계적으로 분할한다.
- 구조 기반 청킹 (Structure-Based Chunking): 텍스트의 문장, 단락, 섹션 헤더와 같은 자연적인 경계를 분할 기준으로 사용한다. 텍스트의 논리적 흐름을 보존하여 맥락 손실을 최소화하는 것을 목표로 한다.
- 재귀적 청킹 (Recursive Chunking): 고정 길이와 구조 기반 청킹의 장점을 결합한 보다 정교한 접근법이다. 가장 높은 우선순위의 구분자로 먼저 텍스트를 분할하고, 청크 크기가 여전히 너무 크면 다음 우선순위의 구분자를 사용하여 분할을 반복한다.
- 시맨틱 청킹 (Semantic Chunking): 텍스트의 내용에 담긴 의미적 유사성을 기반으로 청크 경계를 식별하는 방법이다. 문장 또는 문장 그룹을 임베딩하여 의미적 유사도가 낮은 지점(break point)을 찾아 분할한다.
- Parent-Document Retriever 패턴: 검색 정확도(작은 청크)와 풍부한 컨텍스트(큰 청크)라는 두 가지 상충되는 목표를 동시에 달성하기 위한 하이브리드 전략이다. 두 가지 계층의 청크를 생성한다: 검색을 위한 작은 "자식(Child)" 청크와 LLM에 주입될 더 큰 "부모(Parent)" 청크이다.
- LLM 기반 및 에이전트 기반 청킹: 최신 연구 동향을 반영하는 실험적인 방법론이다. 규칙 기반 또는 통계 기반의 청킹을 넘어, LLM이나 AI 에이전트가 텍스트의 컨텍스트, 의미, 구조를 파악하여 동적으로 최적의 청크 경계를 결정한다.
| 청킹 전략 | 작동 원리 | 복잡성 | 장점 | 단점 | 유스케이스 |
|---|---|---|---|---|---|
| 고정 길이 | 문자/토큰 수 기반 분할 | 낮음 | 단순성, 효율성, 균일한 크기 | 맥락 손실, 구조 무시 | 로그, 단순 FAQ, 짧은 문서 |
| 구조 기반 | 문장/단락 경계 기반 | 낮음 | 맥락 보존, 자연스러운 분할 | 불균일한 크기, 토큰 한계 | 기사, 보고서, 단락 중심 문서 |
| 재귀적 | 우선순위 구분자 기반 계층적 분할 | 중간 | 구조 보존, 유연성 | 구현 복잡성, 과분할 | 논문, 매뉴얼, 비정형 텍스트 |
| 시맨틱 | 의미적 유사성 기반 분할/병합 | 중간-높음 | 높은 의미 관련성, 정확성 | 구현 복잡, 가변적 크기 | 학술 논문, 기술 매뉴얼 |
| Parent-Document | 2단계 계층적 청크 | 높음 | 검색 정확성, 풍부한 컨텍스트 | 구현 복잡, 중복 저장 | 장문 분석, 종합 매뉴얼 |
| LLM/에이전트 | LLM의 추론 활용 | 매우 높음 | 인간 수준의 맥락 이해 | 실험적, 높은 비용 | 법률, 의료 등 복잡 문서 |