LLM 고도화를 위한 프레임워크
저자: 김성중 · 작성일: 2025-08-15 00:00:00 · 분야: LLM
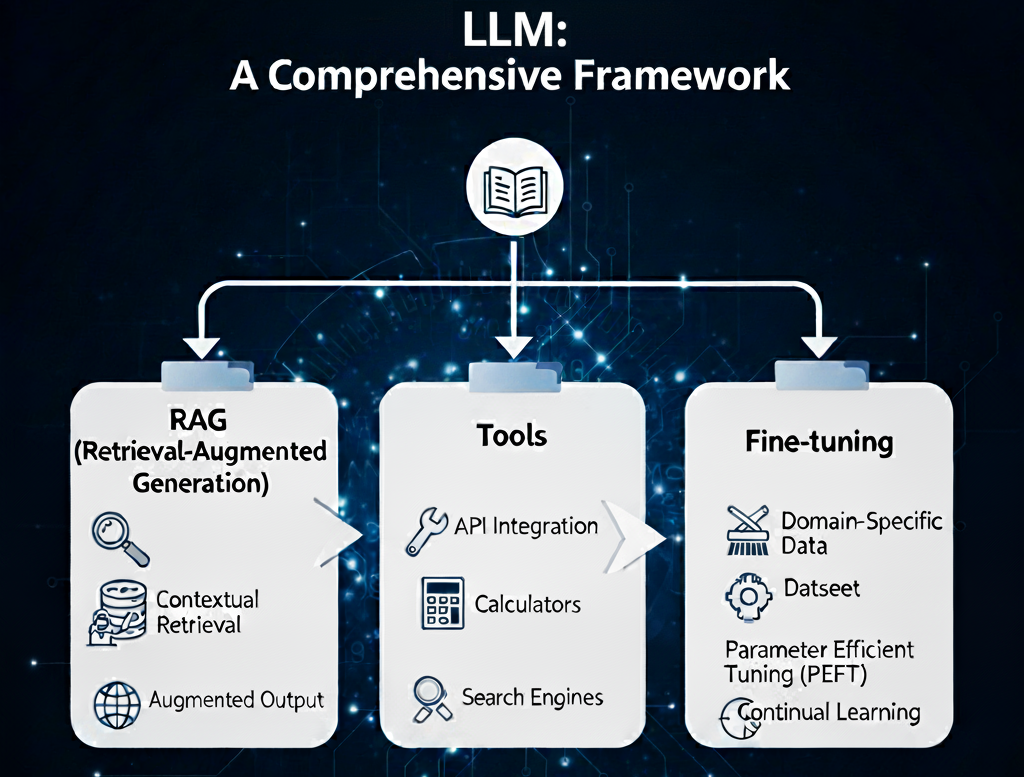
사전 훈련된 대규모 언어 모델(LLM)은 인상적인 능력을 보여주지만, 본질적으로 정적인 훈련 데이터에 의존한다는 근본적인 한계를 가지고 있습니다. 이러한 한계는 '지식 단절(knowledge cutoff)' 현상, 즉 특정 시점 이후의 정보를 알지 못하는 문제로 이어지며, 실시간 정보에 접근하거나 외부 시스템과 상호작용하여 현실 세계에서 특정 작업을 수행하는 능력이 부재합니다. 이로 인해 모델이 사실과 다른 정보를 생성하는 '환각(hallucination)' 현상이 빈번하게 발생하기도 합니다.
이러한 문제를 극복하기 위해 업계는 세 가지 핵심적인 고도화 패러다임에 집중하고 있습니다.
세 가지 기술에 대한 분석
- 검색 증강 생성 (Retrieval-Augmented Generation, RAG): 외부의 동적 지식을 모델에 주입하는 기술입니다.
- 도구 사용 (Tool Use, Function Calling): 모델의 능력을 외부 행동으로 확장하는 기술입니다.
- 미세조정 (Fine-Tuning): 모델의 핵심적인 행동 양식과 스타일을 전문화하는 기술입니다.
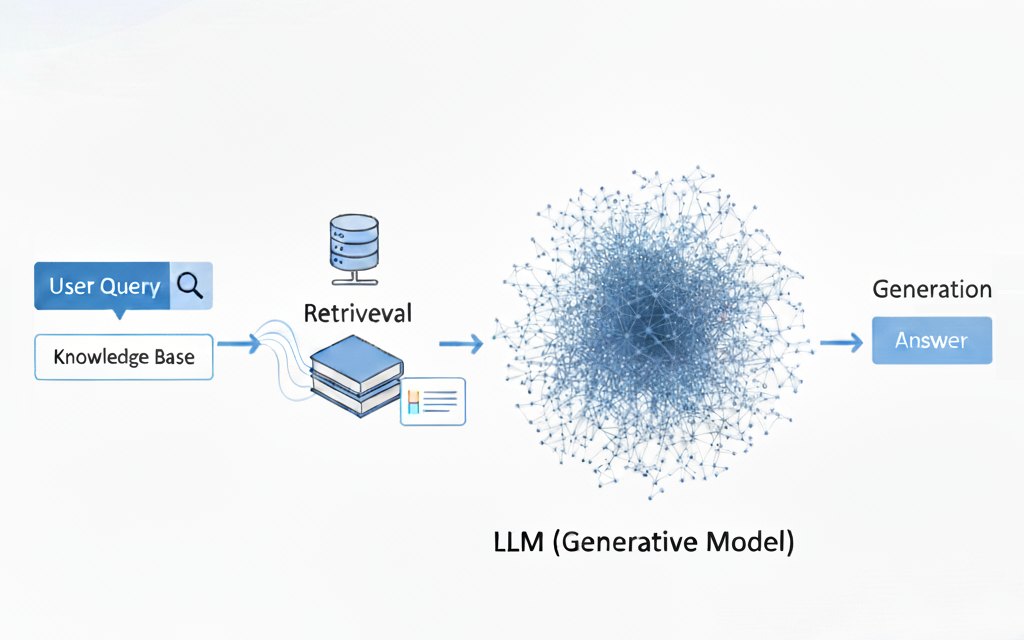
검색 증강 생성(RAG): 동적 외부 지식의 통합
RAG는 LLM을 외부의 신뢰할 수 있는 지식 베이스에 연결하여 모델의 성능을 향상시키는 아키텍처 패턴입니다. 이 기술은 모델이 답변을 생성하기 전에 실시간으로 검색된 구체적이고 검증 가능한 정보에 응답을 근거하게 함으로써 작동합니다. 핵심 원리는 지식 저장소와 LLM의 추론 능력을 분리하여, 모델 자체를 재훈련하지 않고도 지식을 독립적으로 업데이트할 수 있도록 하는 것입니다.
1단계: 데이터 수집 및 인덱싱
이 프로세스는 지식 베이스를 검색 가능한 상태로 준비하는 단계입니다.
- 데이터 소싱 및 청킹(Chunking): PDF, HTML 등 다양한 형식의 문서를 수집하여 관리하기 쉬운 작은 단위인 '청크(chunk)'로 분할합니다. 청크의 크기와 분할 전략은 검색 품질에 직접적인 영향을 미치는 중요한 설계 결정 사항입니다.
- 임베딩 및 벡터화(Embedding and Vectorization): 각 청크는 임베딩 모델을 통해 텍스트의 의미론적 의미를 포착하는 숫자 표현, 즉 '임베딩 벡터'로 변환됩니다.
- 벡터 데이터베이스 인덱싱: 생성된 임베딩 벡터들은 효율적인 유사도 검색을 위해 Pinecone이나 FAISS와 같은 특화된 벡터 데이터베이스에 저장 및 인덱싱됩니다.
2단계: 검색 및 생성
- 쿼리 임베딩: 사용자의 질의 역시 동일한 임베딩 모델을 사용하여 벡터로 변환됩니다.
- 시맨틱 검색(Semantic Search): 쿼리 벡터와 데이터베이스 내 벡터들을 비교하여 의미론적으로 가장 유사한 상위 K개의 텍스트 청크를 찾아냅니다. 더 발전된 방식으로는 시맨틱 검색과 키워드 검색을 결합한 하이브리드 검색이나, 더 구조화된 검색을 위해 지식 그래프(Knowledge Graph)를 활용하기도 합니다.
- 컨텍스트 증강("프롬프트 스터핑"): 검색된 텍스트 청크들은 원본 사용자 질의와 함께 LLM의 프롬프트 내에 삽입됩니다.
- 생성: LLM은 이 증강된 프롬프트를 기반으로, 제공된 컨텍스트를 우선적으로 활용하여 최종 답변을 생성합니다.
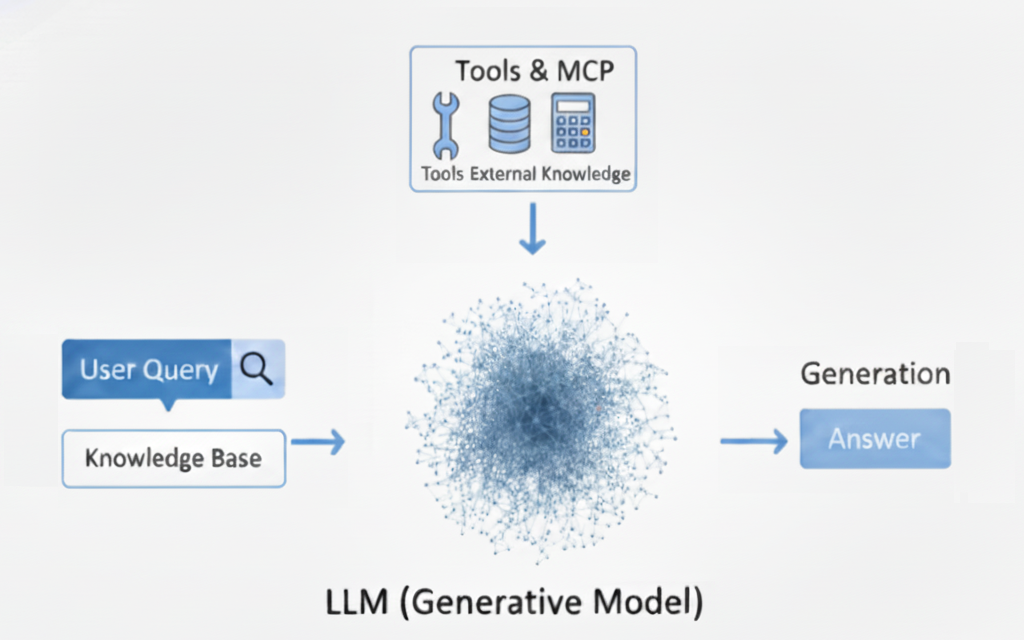
도구 사용(Function Calling): LLM의 능력을 행동으로 확장
'함수 호출(Function Calling)'로 구현되는 도구 사용은 LLM이 외부 시스템 및 API와 상호작용할 수 있도록 하는 기능입니다.
이 기능을 통해 LLM은 단순히 텍스트를 생성하는 것을 넘어, 실행할 함수와 전달할 인수를 명시하는 구조화된 데이터 객체(주로 JSON 형식)를 생성할 수 있습니다.
이는 LLM을 수동적인 정보 소스에서 작업을 수행하고, 실시간 데이터를 검색하며, 워크플로우를 자동화할 수 있는 능동적인 에이전트로 변모시킵니다.
여기서 중요한 점은 LLM이 직접 코드를 실행하는 것이 아니라, 별도의 결정론적 프로그램이 실행할 '명령어'를 생성한다는 것입니다.
함수 호출의 생명주기
- 함수 정의: 개발자는 LLM에게 사용 가능한 '도구' 또는 함수의 목록을 제공합니다. 여기에는 함수의 이름, 설명, 그리고 매개변수 스키마(예: JSON Schema)가 포함됩니다.
- 사용자 의도 인식: LLM은 사용자의 자연어 프롬프트를 분석하여 특정 행동이 필요한지, 그리고 어떤 도구가 적절한지를 판단합니다.
- 구조화된 JSON 생성: 도구가 필요하다고 판단되면, LLM은 텍스트 대신 선택된 함수의 이름과 추출된 인수를 포함하는 JSON 객체를 출력합니다 (예: {"function": "get_current_weather", "city": "London"}).
- 외부 실행: 애플리케이션 코드는 이 JSON을 파싱하여 해당 함수(예: 날씨 API)를 호출하고 결과(예: "섭씨 24도, 맑음")를 수신합니다.
- 응답: 함수 호출의 결과는 다음 차례에 LLM에게 다시 입력되어, 모델이 해당 데이터를 사용자의 질문에 대한 자연어 응답으로 종합할 수 있게 합니다.
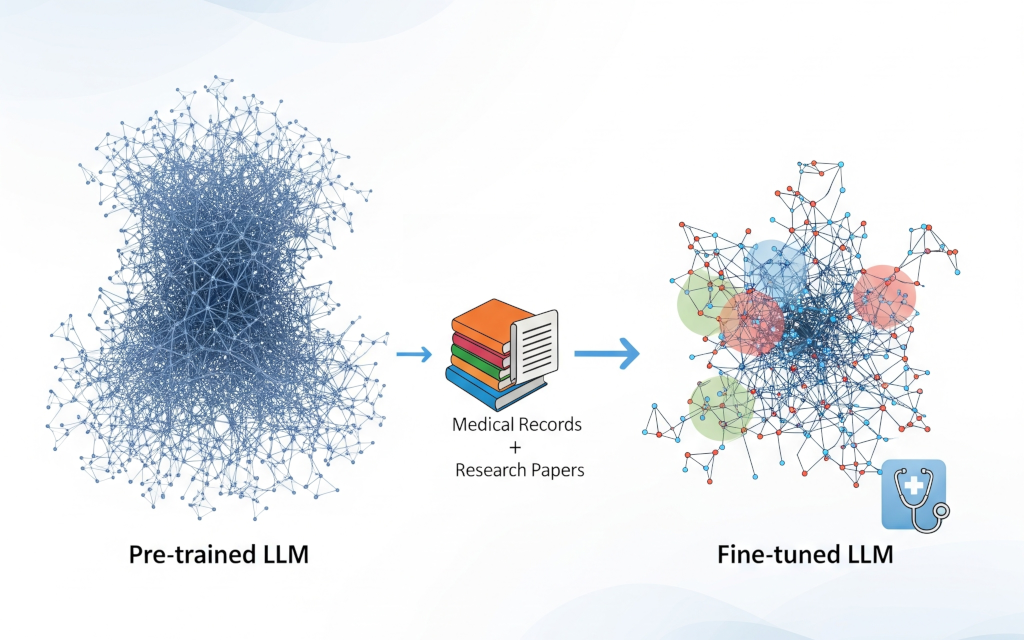
미세조정(Fine-Tuning): 모델의 핵심 지능 전문화
미세조정은 사전 훈련된 '기본(base)' 모델을 가져와 더 작고, 전문화되었으며, 일반적으로 레이블이 지정된 데이터셋으로 추가 훈련을 계속하는 과정입니다.
RAG와 달리, 미세조정의 주된 목적은 모델에 새로운 사실적 지식을 가르치는 것이 아닙니다.
대신, 모델의 행동, 즉 스타일, 톤, 형식 또는 분류나 요약과 같은 특정 작업을 수행하는 능력을 조정하는 데 그 목표가 있습니다.
이는 모델에게 특정 방식으로 생각하거나 응답하는 법을 가르치는 과정입니다.
방법론 비교 분석
- 전체 미세조정(Full Fine-Tuning): 이 방법은 사전 훈련된 모델의 모든 가중치와 매개변수를 업데이트합니다. 계산 비용이 많이 들고 상당한 데이터와 하드웨어가 필요하지만, 최상의 성능을 낼 수 있는 잠재력을 가집니다.
- 매개변수 효율적 미세조정(Parameter-Efficient Fine-Tuning, PEFT): 모델의 대부분 매개변수를 고정(freeze)하고, 새롭거나 기존의 가중치 중 극히 일부만 훈련하는 기술군입니다. 이는 계산 및 메모리 요구 사항을 극적으로 줄여 미세조정의 접근성을 높입니다.
- LoRA (Low-Rank Adaptation): 원본 가중치는 고정된 상태로 두고, 작고 훈련 가능한 '어댑터(adapter)' 레이어를 모델에 주입하는 인기 있는 PEFT 방법입니다. 이는 훈련과 저장 모두에서 매우 효율적입니다.
- QLoRA (Quantized LoRA): 기본 모델을 4비트와 같은 더 낮은 정밀도로 양자화하여 메모리 사용량을 더욱 줄이는, LoRA의 한층 더 효율적인 버전입니다. 이를 통해 매우 큰 모델도 일반 소비자용 하드웨어에서 미세조정할 수 있게 됩니다.
| 구분 | RAG (검색 증강 생성) | 도구 사용 (함수 호출) | 미세조정 (Fine-Tuning) |
|---|---|---|---|
| 주요 목표 | 외부 지식 주입 | 외부 행동 활성화 | 내부 행동 수정 |
| 데이터 최신성 | 실시간/동적 | 실시간/요청 시 | 정적/특정 시점 |
| 비용 구조 | 낮은 초기 비용, 높은 운영 비용 | 호출당 운영 비용 | 높은 초기 비용, 낮은 운영 비용 |
| 구현 복잡성 | 중간 (파이프라인 엔지니어링) | 중간 (API 통합 및 보안) | 높음 (MLOps 및 데이터 큐레이션) |
| 환각 제어 | 외부 사실에 근거 | 사실적 API 데이터 제공 | 추론 오류 감소 |
| '진실'의 원천 | 외부 지식 베이스 | 외부 API/도구 | 모델의 내부 가중치 |
| 확장성 | 지식 베이스 크기에 따라 확장 | 도구/API 수에 따라 확장 | 지식 확장을 위해 재훈련 필요 |
| 설명 가능성 | 높음 (출처 인용 가능) | 높음 (행동 추적 가능) | 낮음 (불투명한 내부 가중치) |
결론: 미래를 위한 일관된 LLM 전략 종합
RAG, 도구 사용, 미세조정 사이의 선택은 기술적 선호의 문제가 아니라, 해결하고자 하는 문제의 본질에 의해 결정되는 전략적 결정입니다.
문제는 지식의 부족인가, 행동의 부재인가, 아니면 행동 양식의 불일치인가? 이 질문에 대한 답이 올바른 길을 제시합니다.
가장 강력하고 가치 있는 LLM 애플리케이션은 필연적으로 하이브리드 시스템이 될 것입니다.
미래는 전문화된 추론을 위한 미세조정된 '두뇌', 동적인 '기억'을 위한 RAG 시스템, 그리고 '행동'을 위한 도구 집합을 완벽하게 통합하는 정교한 에이전트 아키텍처를 만드는 데 있습니다.
이러한 기술들의 진화는 더 자율적이고, 유능하며, 신뢰할 수 있는 AI 시스템의 미래를 예고합니다.
이 세 가지 핵심 기둥의 전략적 적용과 결합을 숙달하는 것이 차세대 성공적인 AI 기반 제품 및 서비스의 결정적인 특징이 될 것입니다.
Comments
Sophia Carter
2 days ago
Great insights into the future of AgentOps! The points about AI sophistication and system integration are particularly relevant.
Ethan Walker
1 day ago
I agree with Sophia. The emphasis on security and ethics is also crucial as we move forward.
Related Posts
AI Agents
Maximizing Efficiency with AgentOps
Learn how to optimize your business processes using AgentOps for increased productivity and reduced costs.