SFT: AI 개발 패러다임의 전환
저자: 김성중 · 작성일: 2025-07-01 00:00:00 · 분야: LLM
과거의 AI 개발이 '창조'의 영역이었다면, 이제는 사전 학습된 거대 언어 모델을 특정 목적에 맞게 '적응'시키는 시대로 전환되었습니다. 지도 미세조정(SFT)은 이 새로운 패러다임의 중심에서, 범용 AI를 당신만의 전문 AI로 변모시키는 가장 강력하고 효율적인 기술입니다.
대규모 언어 모델(Large Language Models, LLM)은 수천억 개의 파라미터를 가진 파운데이션 모델(Foundation Model)으로 방대한 양의 텍스트 데이터로 사전 학습(pre-training)되어 광범위한 언어적 지식과 추론 능력을 갖춘 거대 모델을 기반이다. Fine tuning은 이를 특정 목적에 맞게 미세하게 조정하는 방식을 채택하고 있다.
이 새로운 패러다임의 중심에는 지도 미세조정(Supervised Fine-Tuning, SFT) 이라는 강력한 기술이 자리 잡고 있다. 예를 들어, 일반적인 대화가 가능한 LLM을 법률 문서 분석, 의료 상담, 혹은 특정 기업의 내부 정책에 대한 질의응답 시스템으로 변모시키는 과정의 핵심이 바로 SFT이다. 이 과정을 통해 모델의 응답 정확성과 신뢰도를 높이고, 사용자의 구체적인 요구사항을 충족시킴으로써 LLM의 실질적인 가치를 극대화할 수 있다.
SFT (Supervised Fine-Tuning)
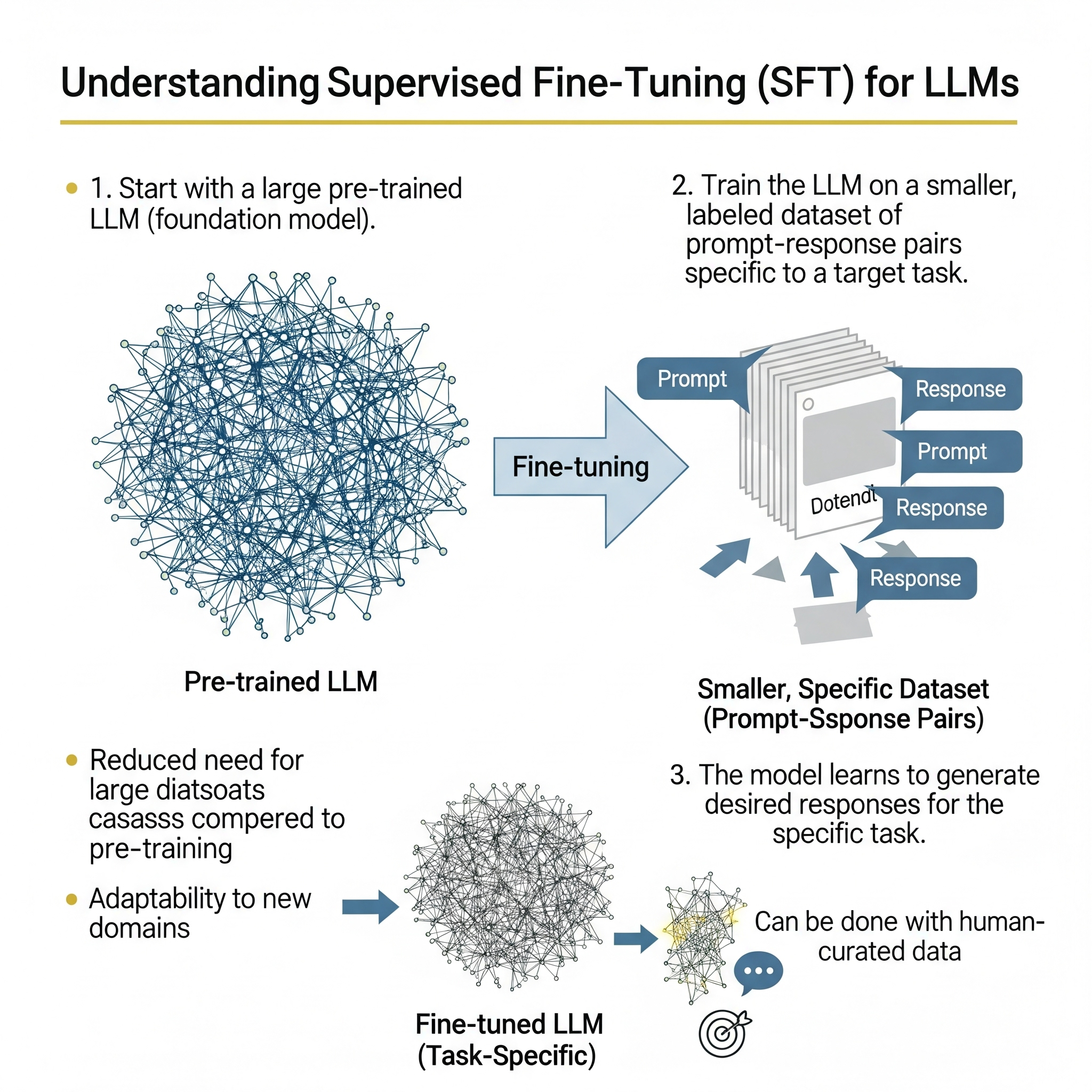
지도 미세조정(Supervised Fine-Tuning, SFT)은 이미 방대한 양의 비정형 텍스트 데이터로 사전 학습(pre-trained)을 마친 언어 모델을, 특정 작업(task)에 특화시키기 위해 레이블이 지정된(labeled) 데이터셋으로 추가 학습을 진행하는 지도 학습(supervised learning) 기반의 최적화 기법이다. 사전 학습을 통해 모델이 언어의 일반적인 문법, 의미, 문맥, 그리고 세상에 대한 상식까지 습득했다면, SFT는 이 지식을 바탕으로 특정 질문에 어떻게 대답해야 하는지, 혹은 특정 지시를 어떻게 수행해야 하는지 구체적인 '행동 양식'을 가르치는 과정이라 할 수 있다.
Gemma 3
Gemma는 생성형 인공지능 (AI) 모델 제품군으로, 질문 답변, 요약, 추론을 비롯한 다양한 생성 작업에 사용할 수 있습니다. Gemma 모델은 개방형 가중치로 제공되며 책임감 있는 상업적 사용을 허용하므로 자체 프로젝트 및 애플리케이션에서 모델을 조정하고 배포할 수 있습니다.
Google의 Gemma 3는 Gemini 모델군과 동일한 연구 및 기술을 기반으로 구축된 최첨단 경량 오픈 모델입니다. 이 모델은 텍스트와 이미지를 모두 처리할 수 있는 멀티모달 기능을 갖추고 있으며, 본질적으로는 이전 토큰을 기반으로 다음 토큰을 예측하는 디코더-온리(decoder-only) 트랜스포머 아키텍처를 따릅니다. 특히 140개 이상의 언어를 지원하는 다국어 능력은 번역과 같은 언어 간 변환 작업에 강력한 초기 기반을 제공합니다.
SFT (Supervised Fine-Tuning)
지도 미세조정(Supervised Fine-Tuning, SFT)은 이미 방대한 양의 비정형 텍스트 데이터로 사전 학습(pre-trained)을 마친 언어 모델을, 특정 작업(task)에 특화시키기 위해 레이블이 지정된(labeled) 데이터셋으로 추가 학습을 진행하는 지도 학습(supervised learning) 기반의 최적화 기법이다. 사전 학습을 통해 모델이 언어의 일반적인 문법, 의미, 문맥, 그리고 세상에 대한 상식까지 습득했다면, SFT는 이 지식을 바탕으로 특정 질문에 어떻게 대답해야 하는지, 혹은 특정 지시를 어떻게 수행해야 하는지 구체적인 '행동 양식'을 가르치는 과정이라 할 수 있다.
- 사전 학습된 모델(Base Model) 선택: SFT의 출발점은 항상 사전 학습된 파운데이션 모델이다. 이 모델은 수십억에서 수조 개의 단어로 구성된 거대한 코퍼스를 통해 '다음 단어 예측(next-token prediction)'과 같은 비지도 학습 목표를 수행하며, 언어에 대한 깊고 넓은 이해를 내재화한 상태다. 이 단계에서 모델은 이미 강력한 언어적 기반을 갖추고 있으므로, SFT는 처음부터 시작하는 것이 아니라 이미 구축된 견고한 토대 위에 전문 지식을 쌓아 올리는 과정이다.
- 레이블된 데이터셋 준비: SFT의 성패를 좌우하는 가장 중요한 요소는 학습 데이터의 품질이다. 이 단계에서는 미세조정의 목표가 되는 특정 작업을 잘 나타내는 고품질의 데이터셋을 구축한다. 이 데이터셋은 주로 '입력-출력(input-output)' 또는 '지시-응답(instruction-response)' 쌍의 형태로 구성된다. 예를 들어, 감성 분석 모델을 만든다면 "이 영화 정말 감동적이었어"라는 입력에 '긍정'이라는 출력을, 의료 챗봇을 만든다면 환자의 증상 설명에 대해 의사의 정확한 진단명을 출력으로 짝지어주는 식이다. 이 데이터셋은 인간 전문가에 의해 신중하게 작성되거나 검수되는 경우가 많으며, 사전 학습에 사용된 데이터에 비해 그 양은 훨씬 적지만 품질은 매우 높아야 한다.
- 지도 학습 기반 가중치 업데이트: 준비된 레이블 데이터셋을 사용하여 모델을 추가로 훈련시킨다. 이 과정은 전형적인 지도 학습 루프를 따른다.
- 순전파(Forward Pass): 데이터셋의 각 입력(instruction)을 모델에 넣어 예측된 출력(prediction)을 생성한다.
- 손실 계산(Loss Calculation): 모델의 예측과 데이터셋에 명시된 실제 정답(ground truth label) 간의 차이를 측정하기 위해 손실 함수(loss function), 주로 교차 엔트로피 손실(cross-entropy loss)을 사용한다. 이 손실 값은 모델이 얼마나 '틀렸는지'를 정량적으로 나타낸다.
- 역전파 및 최적화(Back-propagation & Optimization): 계산된 손실을 최소화하는 방향으로 모델의 내부 파라미터(가중치와 편향)를 조정한다. 이 과정은 역전파 알고리즘을 통해 손실 기울기(gradient)를 계산하고, Adam과 같은 최적화 알고리즘을 사용해 가중치를 업데이트함으로써 이루어진다. 이 사이클을 전체 데이터셋에 대해 여러 번(epochs) 반복하면서 모델은 점차 정답과 유사한 출력을 생성하도록 미세 조정된다.
Gemma 3
모델 개요
사전 학습된(pre-trained) 버전과 지시문 최적화(instruction-tuned) 범용 버전으로 제공되며, 각각 1B, 4B, 12B, 27B의 네 가지 크기로 제공되어 다양한 규모의 작업에 적용할 수 있습니다. Gemma 3의 가장 큰 특징은 오픈 가중치(open weights)를 채택하여 특정 사용 사례나 도메인에 맞게 모델을 자유롭게 수정하고 파인튜닝할 수 있다는 점입니다. 또한, 텍스트뿐만 아니라 이미지를 이해할 수 있는 멀티모달(multimodal) 기능을 지원하여 그 활용 범위를 크게 확장했습니다. 이러한 특성 덕분에 Gemma 3는 학계와 산업계 연구자 및 개발자들에게 특정 과업 수행 성능을 극대화할 수 있는 강력한 기반을 제공합니다.
세부적인 분석에 따르면 코딩이나 OCR과 같은 특정 작업에서 일관성 없는 성능을 보이거나, 지나치게 신중한 후처리 정렬(post-training alignment)로 인해 사용자 경험에서 질적인 문제가 발생할 수 있다는 한계점도 드러납니다.
- 이미지 및 텍스트 입력: 멀티모달 지원하며 이미지와 텍스트를 입력하여 시각적 데이터를 이해하고 분석할 수 있습니다.
- 128K 토큰 컨텍스트: 큰 입력 컨텍스트를 입력할 수 있어 많은 데이터를 분석하고 복잡한 문제를 해결할 수 있습니다.
- 함수 호출: 프로그래밍 인터페이스를 사용하는 자연 언어 인터페이스를 빌드합니다.
- 다양한 언어 지원: 140개가 넘는 언어를 지원하여 사용 중인 언어로 작업이 가능합니다.
- 개발자 친화적인 모델 크기: 작업 및 컴퓨팅 리소스에 가장 적합한 모델 크기 (1B, 4B, 12B, 27B)와 정밀도 수준을 선택 가능합니다.
장점
큰 장점 중 하나는 탁월한 연산 효율성입니다. 작은 1B 모델은 사전 채우기(prefill) 작업에서 초당 2,585 토큰이라는 놀라운 속도를 처리하여, 실시간 애플리케이션에서 거의 즉각적인 응답이 가능하게 합니다. 하드웨어 요구사항이 낮아 배포 및 운영 비용을 크게 절감할 수 있습니다. 이는 대규모 클라우드 인프라에 접근할 수 있는 기업뿐만 아니라 더 넓은 범위의 개발자들이 첨단 AI에 접근할 수 있도록 합니다. 4B, 12B, 27B 모델은 텍스트와 이미지를 모두 처리하는 멀티모달 입력을 기본적으로 지원합니다. 새로운 토크나이저와 개선된 데이터 혼합 방식은 140개 이상의 언어를 지원하여, 주로 영어에 초점을 맞췄던 Gemma 2에 비해 크게 향상된 다국어 능력을 보여줍니다.
장점
복잡한 코드 생성이나 디버깅보다는 기본 코딩 및 프로토타이핑에 더 적합합니다. 큰 컨텍스트 창을 가지고 있음에도 불구하고, 일부 벤치마크에서는 Mistral 3.1과 같은 경쟁 모델에 비해 긴 컨텍스트 작업에서 뒤처지는 모습을 보입니다. 몇 번의 프롬프트 이후에 반복적인 문장을 무한히 출력하는 현상을 보이거나, 사용자가 오류를 지적해도 스스로 수정하지 못하는 경우가 있는 것으로 나타났습니다. 게임과 같은 통제된 환경에서 '민감한 주제'를 다룰 때에도 모델은 "지나치게 신중한 태도를 취하며" 지시를 거부하거나 심지어 도움 요청 전화번호를 제공하는 경우가 있습니다.
Comments
Sophia Carter
2 days ago
Great insights into the future of AgentOps! The points about AI sophistication and system integration are particularly relevant.
Ethan Walker
1 day ago
I agree with Sophia. The emphasis on security and ethics is also crucial as we move forward.
Related Posts
AI Agents
Maximizing Efficiency with AgentOps
Learn how to optimize your business processes using AgentOps for increased productivity and reduced costs.